ㅁ Data Mining이란?
데이터 마이닝(Data Mining)은 대규모 데이터 저장소에서 유용한 정보를 자동으로 탐색하는 과정을 뜻한다.
데이터 마이닝 기법은 대규모 데이터 안에서 지나칠 수 있는 새롭고 유용한 패턴을 탐색하는 등의 목적에 적용되고 있다.
Knowledge Discovery in Database[(:KDD) 데이터베이스에서 지식탐사]는 데이터 마이닝을 위한 입력 데이터를 변환해 유용한 정보를 도출하는 전체 과정이다. 입력데이터로는 다양한 형식(일반파일, 스프레드시트, 관계 테이블 등)으로 저장되고 있다.

Preprocessing(전처리)의 목적은 입력 데이터를 변환으로 이후 분석에 적합한 형식을 맞추기 위함이다. Data Preprocessing에 필요한 과정으로는 다양한 소스로부터 데이터를 합하고, 잡음과 중복으로부터 데이터를 정제, 데이터 마이닝의 목적과 관련된 레코드와 특징들만 선택하는 것 등이 있다. 데이터는 대규모로 존재하기 때문에 전체 지식탐사 과정 중 가장 시간이 많이 소모되는 과정이라고 할 수 있다.
Postprocessing(후처리) 과정은 데이터마이닝 결과 중 타당성 있고 유용한 결과만을 의사결정 시스템으로 통합될 수 있게 보장해주는 과정으로 통계적 척도와 가설 검증 방법 또한 후처리에 적용되어 불필요한 데이터 마이닝 결과를 제거하기도 한다.
ㅁData Mining 작업의 종류
1. Predictive tasks (예측 작업)
- 다른 속성의 값들을 기반으로 특정 속성 값을 예측하는 것.
- 예측해야하는 속성은 보통 target(목표) or Dependent variable(종속변수)로 알려져있고,
- 예측을 만드는 데 사용하는 속성으로는 explanatory(설명적) or independent variable(독립변수)로 알려져있다.
2. descriptive tasks (서술 작업)
- 데이터에 숨어있는 관련성을 요약하는 패턴(상관성, 군집, 경향, 궤적, 이상치 등)을 찾아내는 것.
- 탐구적이며 결과의 타당성을 검증하고 설명하기 위해 후처리 기법을 요구
3. Predictive Modeling (예측 모델링)
- 목표 변수를 설명 변수의 함수 모델로 생성하는 작업
- 이산형 목표 변수에 사용하는 classification(분류)와 연속형 목표 변수에 사용하는 regression(회귀)의 유형이 있다.
- 두 작업 모두 목표 변수의 예측 값과 실제 값 사이의 오류를 최소화하는 모델을 학습하는 것이 목표이다.
ex. classification : 마케팅 행사에 참여하는 고객 식별, regression : 지구 온난화의 속도 예측
4. Association Analysis (연관 분석)
- 데이터에 강하게 연관된 특징을 설명하는 패턴을 발견하는데 사용
- 탐지된 패턴은 보통 규칙이나 특징의 부분집합으로 표현되며 탐색 공간의 기하급수적 크기로 인해 흥미로운 패턴을 효율적인
방법으로 추출해내는 것이 목표이다.
5. Cluster Analysis (군집분석)
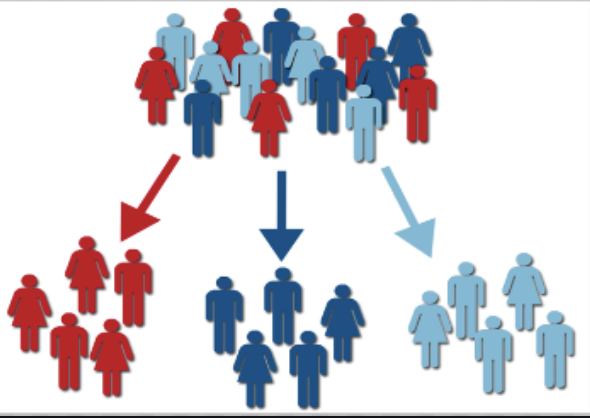
- 주어진 데이터들을 특성에 따라 유사한 것끼리 묶음으로서 각 유형별 특징을 분석하는 기법
6. Anomaly Detection (이상치 탐지)
- 특징이 다른 데이터들과 현저히 다른 관측들을 식별하는 작업으로 anomaly(이상치) 또는 outlier(국외자)로 알려져있다.
- 좋은 이상치 탐지기는 높은 탐지율과 낮은 오탐률을 가져야 한다
'-' 카테고리의 다른 글
| 데이터 품질 (0) | 2019.11.24 |
|---|---|
| 데이터와 데이터 집합 (0) | 2019.11.24 |
| [LINUX] root/일반 계정 su 제한, 해제하는 방법 (1) | 2019.09.03 |
| [MAC OS]MAC에 Android 데이터 가져오기 (0) | 2019.08.14 |
| [API활용] 카카오 api를 활용해 챗봇 만들기 _ 참여신청 승인 (0) | 2019.06.18 |



댓글