ㅁ 데이터 전처리(Data Preprocessing)란?
- 데이터의 품질을 개선하거나 DataMining에 적합한 형태로 원시 데이터를 변환하는 기법
데이터 전처리는 광범위한 분야이고 서로 복잡하게 관련된 여러 전략 기법으로 구성되어 있고 그 중 일부에 대해 공부할 예정이다.
지금 공부할 항목들은 분석을 위한 Data Object와 Attribute를 선택하는 작업과, Attribute를 생성/변경하는 작업의 두 범주로 나뉜다.

1. Aggregation(통계)
: 두개 이상의 객체를 하나의 단일 객체로 결합하는 경우로 특정 Attribute를 통해 통합된다.
ex) 날짜에 대한 값을 365일에서 12개월, 12개월을 1년으로 줄일 수 있다.
: Aggregation(총계)에 대한 동기는 여러가지로 볼 수 있다.
- 데이터 축소에 따른 소형 데이터 집합은 적은 기억 공간과 처리시간을 요구한다
- 저수준 관점 대신 고수준 관점을 제공하여 범위나 규모에 변화를 가져올 수 있다
- Object나 Attribute Group의 행위는 개별 객체나 속성의 행위보다 안정적이다
-> 집계된 수량이 집계되는 개별 객체보다 가변성이 적다
2. Sampling (표본추출)
: 객체의 부분집합을 선택하는 접근법으로 데이터 마이닝에서 흔히 사용 됨
- Sampling without replacement (비복원추출)
: 각 항목 선택 시, 그것을 population(모집단)을 구성하는 모든객체의 집합으로부터 제거
- Sampling with replacement (복원추출)
: Object가 표본으로 선택될 때 그것을 Population(모집단)으로부터 제거하지 않음
※ 희귀 클래스에 대한 분류 모델을 구축할 경우, 희귀 클래스가 표본에 적절하게 표현되는 일이 중요하므로
관심 항목에 대해 상이한 빈도를 수용할 수 있는 표본추출 기법이 필요하다 (충화 표본추출 Startified sampling)
※ 표본 추출과 정보 손실(Sampling and loss of information)
: 표본추출 기법 선택 후 표본 크기를 보자. 표본 크기가 커지면 표본이 대표성을 가질 확률이 높지만 표본 추출의 많은 장점을 잃게 된다.
※ 적당한 표본 사이즈 (Proper Sample size)
3. Dimensionality Reduction (차원 축소)
- 데이터 차원이 증가함에 따라 매우 어려워지는 현상인 "차원의 저주"가 존재한다 (= 차원이 크다고 좋은 것만은 아니다)
- 차원 축소를 위한 선형대수 기법
# PCA : Principal Component Analysis (주성분분석)
# SVD : Singular Value Decomposition (특이 값 분해)
4. Feature subset selection (특징 부분집합)
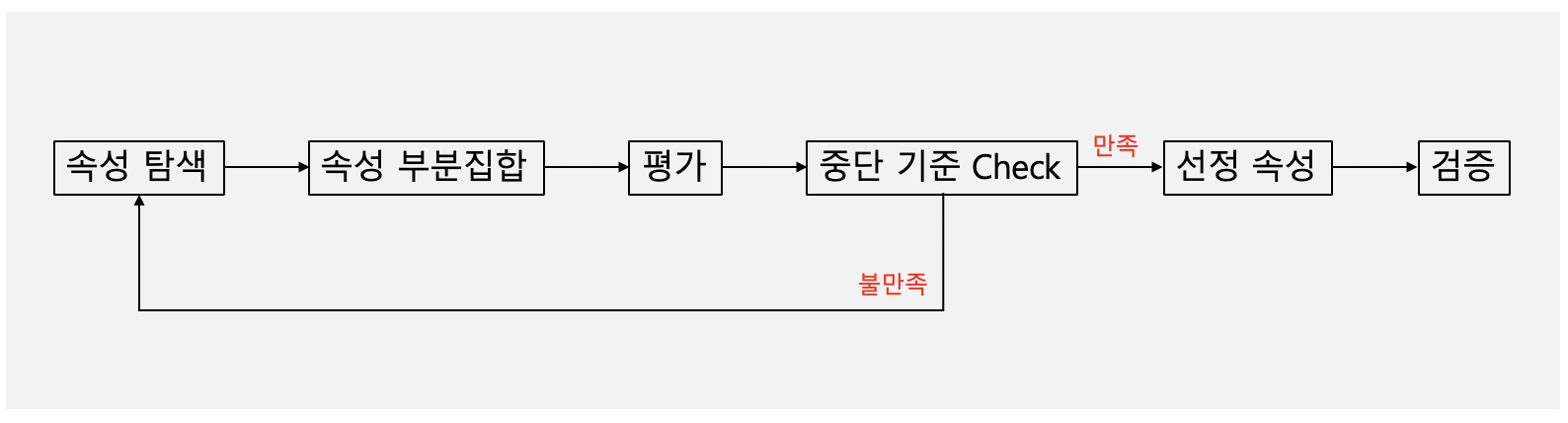
- Redundant Feature(중복특징)
: 한 개 이상의 다른 속성에 포함된 정보의 상당 부분 또는 전체가 중복된 것
- Irrelevant Feature(비관련특징)
: 진행하려는 데이터 마이닝 작업에 거의 불필요한 정보를 포함한 것
ex) 고과 평균을 매기려는 데이터가 있을 때 사번ID는 비관련 특징
일부 중복 특징이나 비관련 특징을 선택하는데 가장 필요로 하는 것은 삽입, 필터, 래퍼 3가지로 정의할 수 있다.
- 삽입 방법 : 알고리즘 자체에서 사용할 속성과 무시할 속성을 결정
- 필터 방법 : 알고리즘 실행 전에 상관관계가 가능한 한 낮은 속성의 집합을 선택하는 등의 방식
- 래퍼(wrapper)방법 : 최상의 부분집합을 발견하기 위해 목표 데이터 마이닝 알고리즘을 블랙박스로 사용
5. Feature creation (특징 생성)
- 원본데이터로부터 특징의 새로운 집합을 생성하는 것
6. Discretization and Binarization (이산화와 이진화)
- Discretization : continuous attribute를 categorical(범주) attribute로 변경
- Binarization : continuous attribute, discrete attribute 모두 binary attribute로 변경
7. Variable Transformation(변수 변환)
- 분석을 위해 불필요한 변수를 제거하고, 변수를 반환하며, 새로운 변수를 생성시키는 작업.
- 변수란 모델링에서 사용되는 것으로 Independent Variable(독립변수), Dependent Variable(종속변수) 또는 기타변수로 분류
Independent Variable : 입력 값 또는 원인을 나타냄
dependent Variable : 결과물 또는 효과를 나타냄
기타 변수 : 기타 여러가지 원인으로 관찰 중인 변수
'-' 카테고리의 다른 글
| 데이터 탐색 (0) | 2019.12.09 |
|---|---|
| 유사도와 비유사도의 척도 (0) | 2019.11.27 |
| 데이터 품질 (0) | 2019.11.24 |
| 데이터와 데이터 집합 (0) | 2019.11.24 |
| 데이터 마이닝이란? (0) | 2019.11.21 |



